即可将网页分享至朋友圈
2月24日,2020 IEEE国际计算机视觉与模式识别会议(IEEE Conference on Computer Vision and Pattern Recognition,简称CVPR)官方公布论文收录结果。我校信息与通信工程学院本科2016级学生王谭在新加坡南洋理工大学Prof. Hanwang Zhang指导和阿里巴巴达摩院的资助下,以第一作者撰写的论文“Visual Commonsense R-CNN”(视觉常识 R-CNN)被CVPR2020接收。这是我校第一位以第一作者在CVPR上发文的本科生。
CVPR是计算机视觉领域的三大世界顶级会议之一。本届CVPR投稿ID破万,最终收到来自世界各地的有效投稿6656篇,接收1470篇,录取率为22%,为近十年来最低。会议将于6月16-19日在美国华盛顿召开
王谭同学的论文“Visual Commonsense R-CNN”针对现有的Vision & Language任务所用Up-Down特征存在的bias较大、缺少构建物体与物体之间关系等问题,从因果推断(Causal Inference)的角度出发,利用Judea Pearl等人在2009年提出的“Do”算子和后门调整算法,结合现有的目标检测框架对现实场景中的物体进行干预(Intervention)。其本质可以简单的理解为“Borrow & Put”。
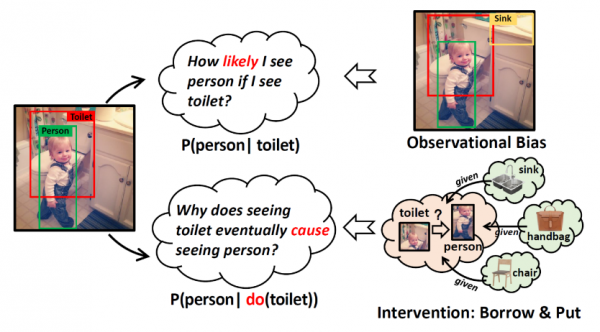
图1:和传统的贝叶斯条件概率对比

图2:视觉常识特征提取框架结构图
其研究和传统的贝叶斯条件概率对比,通过构建一个字典来把广泛存在于其他图片中的物体“borrow”到当前图片中。然后把借来的物体“put”到X、Y周围和X、Y对比,例如上图中的把 sink、handbag、chair等等移到toilet和person周围,然后通过后门调整公式计算干预后的值。最后通过一种自监督学习的方式学习到图片局部物体的更好的表征——我们称之为视觉常识特征。
作者在三个最主要的Vision & Language下游任务中对学习到的特征进行验证,都取得了目前最好结果。其中图片描述任务(Image Captioning)更是在Cider上比原先增长了近2个百分点。(提取框架图见图2,详细计算过程可参考文末链接文章)
因果理论是近一年来开始被计算机视觉学术界关注的全新方向和思路。这项研究除了是因果理论在计算机视觉学术界的推广,同时也和当下被广泛关注的自监督学习联系非常紧密。通过自监督学习可以有效地挖掘数据集中的特征信息,为广泛的计算机视觉下游任务提供便利,但是自监督学习缺乏直接的评价指标,需要耗费大量的实验和时间来验证算法的有效性。王谭希望花费了大量精力完成的这项成果能给学术界带来价值。
王谭,在校期间先后荣获国家奖学金、唐立新奖学金。加权平均分92.8,GPA3.99,前两年专业排名综合排名均位列1/450,所修67门课程中有62门90分以上,获得四川省优毕业生称号。于2019年7月前往新加坡南洋理工大学实习。2019年11月,他以第一作者撰写的论文“Matching Images and Text with Multi-modal Tensor Fusion and Re-ranking”(基于多模态张量融合和重排序的图像文本检索)被第27届国际多媒体会议(The 27th ACM International Conference on Multimedia)接收为Oral(大会演讲)论文。2020年1月,他以共同第一作者完成的论文“Cross-Modal Attention with Semantic Consistence for Image-Text Matching”被人工智能1区期刊TNNLS(IEEE Transactions on Neural Networks and Learning Systems)接收。
相关链接:
论文链接:https://arxiv.org/abs/2002.12204
更多详细的算法代码可参考王谭同学的github repo,欢迎star:https://github.com/Wangt-CN/VC-R-CNN
王谭同学针对该论文用到的因果理论撰写的知乎科普文章:https://zhuanlan.zhihu.com/p/111306353
编辑:林坤 / 审核: / 发布:陈伟

