即可将网页分享至朋友圈
随着计算机视觉技术的发展,各类图片识别和分类软件层出不穷,比如拍照识花草、拍照识字、人脸识别、熊猫识别……如何让计算机软件在图像识别的时候精准度更高、速度更快,是研究者们一直在探讨与追寻的问题。

近日,我校计算机科学与工程学院2018级本科生傅阳烨以第一作者身份在2021年度IEEE国际计算机视觉与模式识别会议(2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR)上发表了一篇题为“Partial Feature Selection and Alignment for Multi-Source Domain Adaptation”的论文,提出了一种新颖的模型框架来解决带类别偏移的多源域领域自适应问题,或许能够让图像识别更准更快。

CVPR是人工智能计算机视觉领域最具权威性的国际顶级会议之一,每年召开一届。在谷歌最新发布的2020年度学术指标(Scholar Metrics)榜单中,CVPR以299的H5指数值排名第5位,人工智能领域排名第1位。近年来,CVPR的投稿量逐年增加,据其官网数据显示,2021年度CVPR总投稿量超过万份,有效投稿数约为7500份,最终有1663篇论文被接收,接收率约为27%。

“识图”模型火眼金睛,更优分类、更准识别
傅阳烨的这篇论文,属于多模态领域自适应的研究热点,研究工作为该方向的前沿研究提供了新颖的模型框架。
2019年,刚刚大二的傅阳烨进入了计算机学院的“拔尖人才培养计划”,在学院未来媒体研究中心徐行副教授指导下进行科研训练和学习。在阅读了几十篇相关文献后,他开始有了对多源域领域自适应的创新想法,并在导师和团队的支持下做出了成果:那就是为计算机的视觉处理过程设计更加智慧的模型,让它能更加精确快速地根据已知数据集的图像为新的未知的图片贴上正确的标签。

对于计算机视觉领域自适应中的图像识别问题而言,需要用多个标签已知的数据集(多源域)的图像来识别未知的数据集(目标域)的图像。这就涉及两个工作:特征选择和特征对齐。可以试想,有一张图片(某个源域中的一个类别),将这个图片放到一个黑盒子(特征提取器)里就会生成一个特征向量,把它记作空间(特征图)里的一个点,因为源域中有许多相同类别的图片,所以将这些图片放到小盒子之后就会生成一团聚集的点,而目标域中本身也有这一类别的图片,把目标域中这一类别的图片放到黑盒子里,将会生成特征图中的另一团点,这个过程称为特征提取。由于源域和目标域在特征图的不同维度上具有不同的相关性,傅阳烨设计了一种特征选择算法来对图像进行特征层面的筛选,使得这两团点能更加精确地描述源域和目标域之间的共同特征。而特征对齐就是把空间中这两团点的距离缩小,让它们相互匹配。通过这样的选择和对齐,计算机就可以识别目标域中我们想要标记的图片,当然,这要建立在源域和目标域的类别数量一样多且类别种类一致的前提下。
那如果源域和目标域类别数量不一样多,且类别种类不一致呢?这种情况我们称为类别偏移。之前研究者的所提出的多源域模型没有讨论类别偏移的问题,而傅阳烨所研究的则是多个源域的类别是包括但不限于目标域类别的,即存在类别偏移的问题。将前人的模型直接应用在带类别偏移的实验中,识别的准确率都呈现出大幅地下降,而傅阳烨的模型则能得到很好的结果。
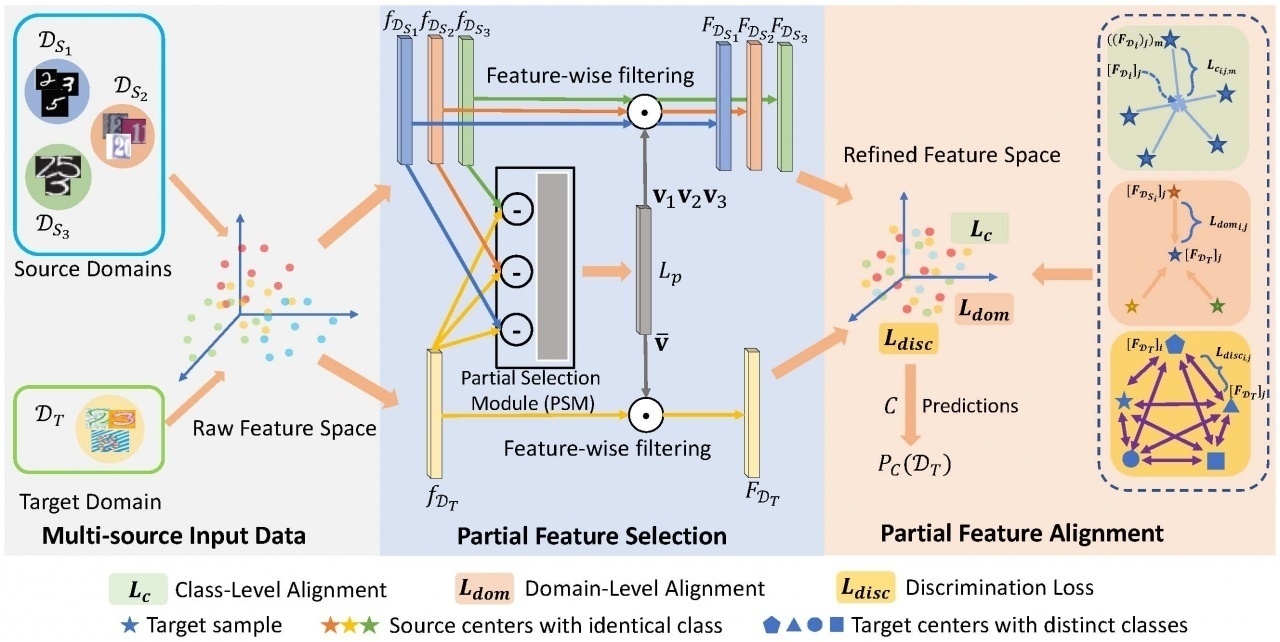
论文提出的PFSA模型框架示意图
他分析了三种多源域类别偏移的情况(多个源域,单一目标域):第一种情况是源域的类别完全相同,且目标域中的类别是源域类别的子集。这里的源域可比作水彩画和蜡笔画,目标域比作粉笔画。源域类别完全相同是指分别用水彩、蜡笔画出的物体种类完全相同(如都有猫、狗、花、车),目标域中的类别是源域类别的子集,是指用粉笔画出的物体一定能在水彩画和蜡笔画中找到相同类别(如猫、狗),而有些类别则可能只在水彩画和蜡笔画中出现(如花、车)。第二种情况则允许源域类别不完全相同,但目标域类别是源域类别的交集的子集。在前面的例子中,假设两个源域水彩画和蜡笔画都有自己独特的类别(如水彩画有额外的鸡,蜡笔画有额外的鸭),此时水彩画中的物体在蜡笔画中不一定能找到相同类别,反之亦然。且粉笔画中的物体一定是水彩画、蜡笔画中共有的物体(如猫、狗)。第三种情况则在源域的类别不完全相同的情况下,只需要目标域中的类别是源域类别的并集的子集,即目标域的类别至少在某一个源域出现,这与第二种情况的区别是尽管水彩画中没有鸭,蜡笔画中没有鸡,粉笔画中也可以出现鸡、鸭。在分析了这三种类别偏移的情况后,他最终使用所设计的部分特征选择和对齐算法PFSA解决了最具普适性的也最具挑战性的类别偏移多源领域自适应问题,即前面所讨论的第三种情况。简单来说,在前面的例子里,模型可以利用带类别标记的水彩画和蜡笔画样本,以及没有类别标记的粉笔画样本,来对未知的粉笔画进行分类。
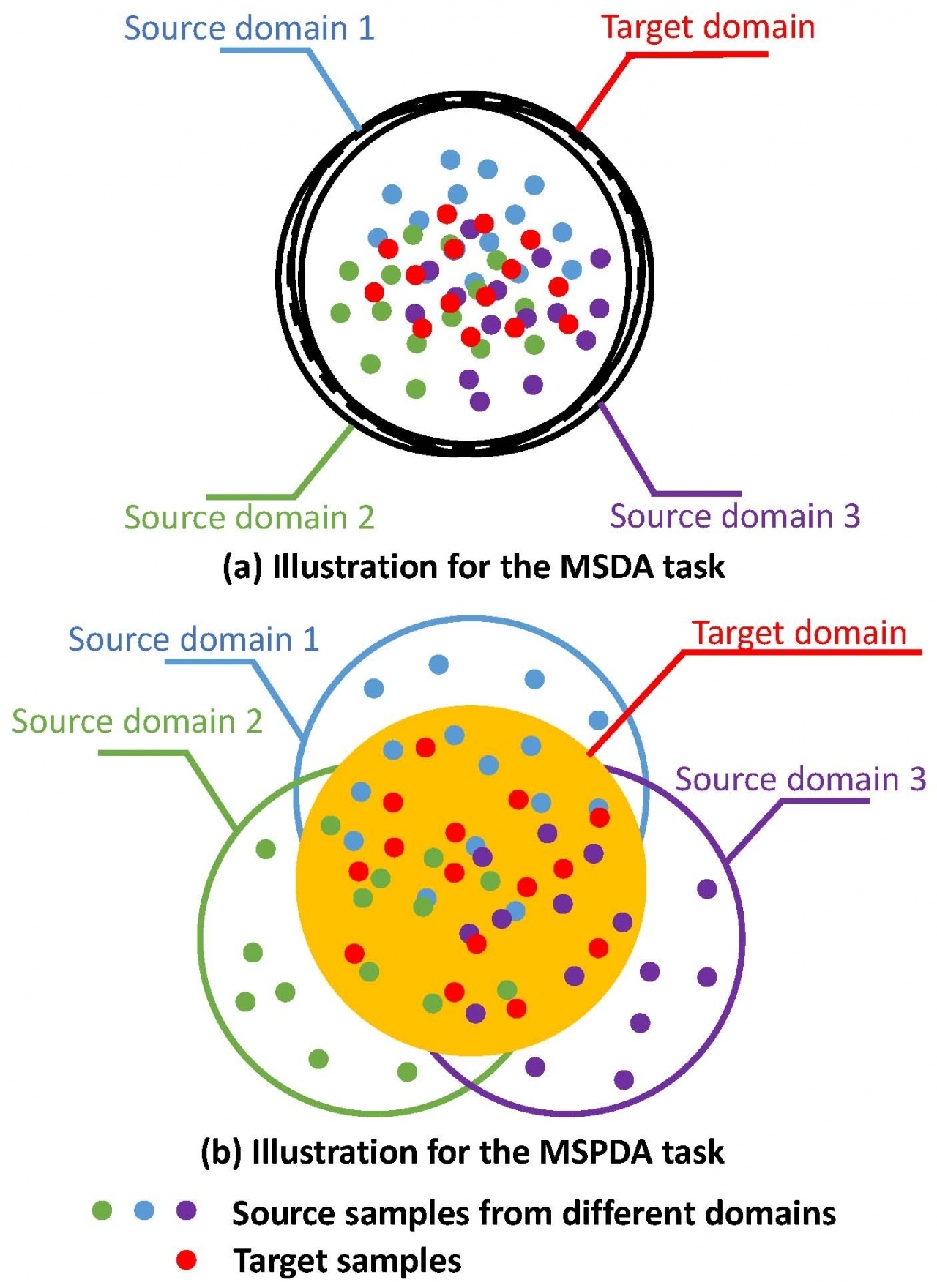
多源域领域自适应中的类别偏移问题
尽管傅阳烨所做的是理论工作,他仍对模型的应用提出了设想,“实际上,我所做的模型关系到一个聚类的问题,就是提取得到特征图后,把相同类别聚合起来,而把不同类别的分隔开来,因此需要进行分类的地方都可以用到这个模型。而且不局限于普通的分类任务,现在大家津津乐道的热门技术,比如人脸识别和目标检测,只要是需要对多个数据集进行不同类别的聚类,都可以应用我们论文里所提出的算法框架。”
计划先行一步,成电学霸始终在进阶
傅阳烨一直是一个有计划的人。刚进入大学,他就给自己制定了规划,决定走科研的道路。大二时,他便加入未来媒体研究中心。当时导师徐行给了他几个选择,考虑到自己数学功底还不错,他就选择了领域适应这个偏理论的方向。
刚开始的时候,他对科研并不是太了解。从加入实验室,到发表第一篇论文,他花了接近2年的时间。“在这其中收获很多,最大的感受就是做科研要能沉下心来,耐得住寂寞。” 傅阳烨说。

在阅读文献的时候,他会找出每一篇论文的亮点、缺陷,总结论文的主要方法,思考论文中的模型和其他论文不一样的地方,以及模型还可以改进的地方。正是因为不断思考、不断积累,他才有了自己的创新想法。
在把想法付出实践的过程中,傅阳烨也遇到了很多困难。从去年5月份他便开始着手实现模型,进行对比实验。由于编码能力不是特别强,在前期一直没有理想的结果。“我一直在纠结是代码写错了,还是模型不好。后来通过跟老师讨论,我和师兄师姐们不断修改版本,发现模型是对的,只是我之前代码有问题。”
模型做出来以后,傅阳烨又发现有一篇已经发表的文章,别人的模型测试结果比自己做的更好。他又赶紧学习相关知识,对自己的模型进行改进,提出了一个比对方更好的模型,最后才顺利被CVPR收录。
说到写论文过程中最难忘的事,傅阳烨笑着说是去年11月他过生日的时候,当时正在做论文的补充材料,结果通宵都在改材料,完全没有机会过生日。忙了一两周以后,等所有材料都弄完了,才想起来给自己过了一个简单的生日。“那段时期时间很紧张,又要忙课程作业,又要写论文,感觉每天都是连轴转。” 傅阳烨说。
对于如何平衡学业和科研,傅阳烨的秘诀是做好规划。在寒暑假的时候,他会对新的学期进行一个大致的规划,而每天晚上他也会写日记,记录一下当天发生了什么,有什么想法,同时列出第二天的规划。正是利用这样高效、有条理的学习方式,傅阳烨做到了学业和科研两手抓,在更优秀的路上奋勇前行。
编辑:何乔 / 审核:何乔 / 发布:陈伟

